Profil discursif d'engagement institutionnel sur l'IA
Analyse documentaire computationnelle (TF-IDF + LDA + lexicon mapping multilingue FR/AR/EN) appliquée aux corpus web des 11 universités publiques marocaines (hors UM5, site de validation empirique réservé). Produit le matériel empirique de la Section 6.5 du papier IJIM (Aarab, Ouifak, El Marzouki, El Moutaqi, 2026, en révision).
Profil normalisé (5 dimensions, somme = 1.0)
| Université | DIRDonnées & | OACCapacité organisationnelle | RAIIA responsable | ESTSensemaking éthique | PVOOrientation valeur | Dominante |
|---|---|---|---|---|---|---|
| UAE | 4.2% | 63.7% | 2.7% | 4.5% | 24.8% | OAC |
| UCAM | 1.7% | 74.5% | 1.0% | 6.8% | 15.9% | OAC |
| UCD | 29.8% | 55.3% | 0.0% | 0.0% | 14.9% | OAC |
| UH1 | 17.9% | 52.6% | 6.7% | 10.4% | 12.3% | OAC |
| UH2C | 14.2% | 57.3% | 12.2% | 7.5% | 8.8% | OAC |
| UIT | 31.7% | 56.7% | 1.8% | 1.0% | 8.8% | OAC |
| UIZ | 9.5% | 51.4% | 2.9% | 7.6% | 28.6% | OAC |
| UM5 | 4.0% | 61.9% | 3.6% | 9.0% | 21.5% | OAC |
| UMI | 5.0% | 65.5% | 12.6% | 0.9% | 16.0% | OAC |
| UMP | 2.4% | 72.0% | 9.7% | 3.5% | 12.4% | OAC |
| USMBA | 1.2% | 73.5% | 2.4% | 3.0% | 19.9% | OAC |
| USMS | 14.0% | 51.2% | 6.2% | 14.5% | 14.1% | OAC |
Visualisations publication-ready
Figures générées par 04_visualise.py (matplotlib, palette IJIM-friendly). Disponibles aussi en PDF dans le repo pour insertion directe dans le manuscrit.
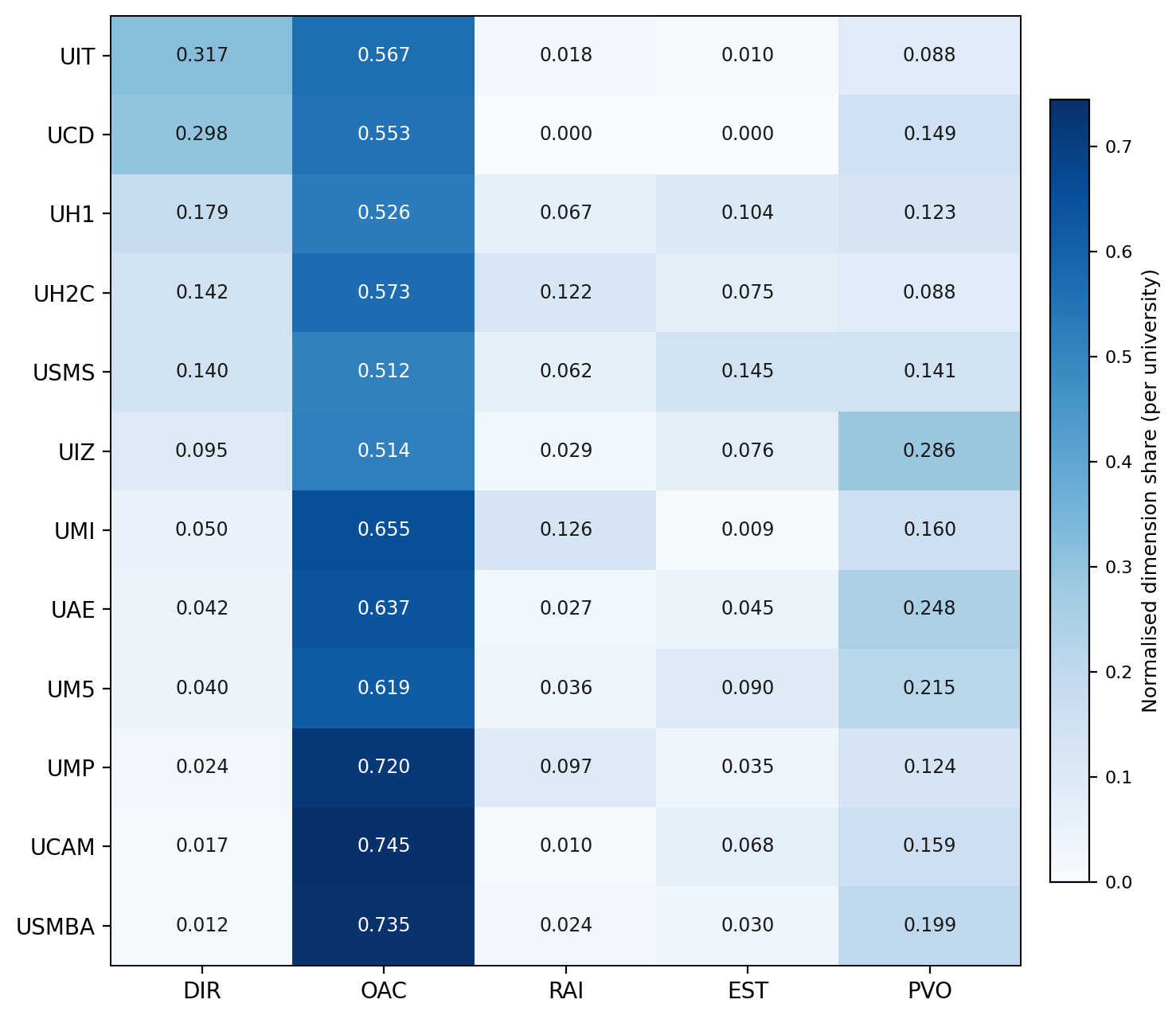
Heatmap 11 universités × 5 dimensions
Vision comparative directe : couleur = part normalisée de chaque dimension dans le discours public.
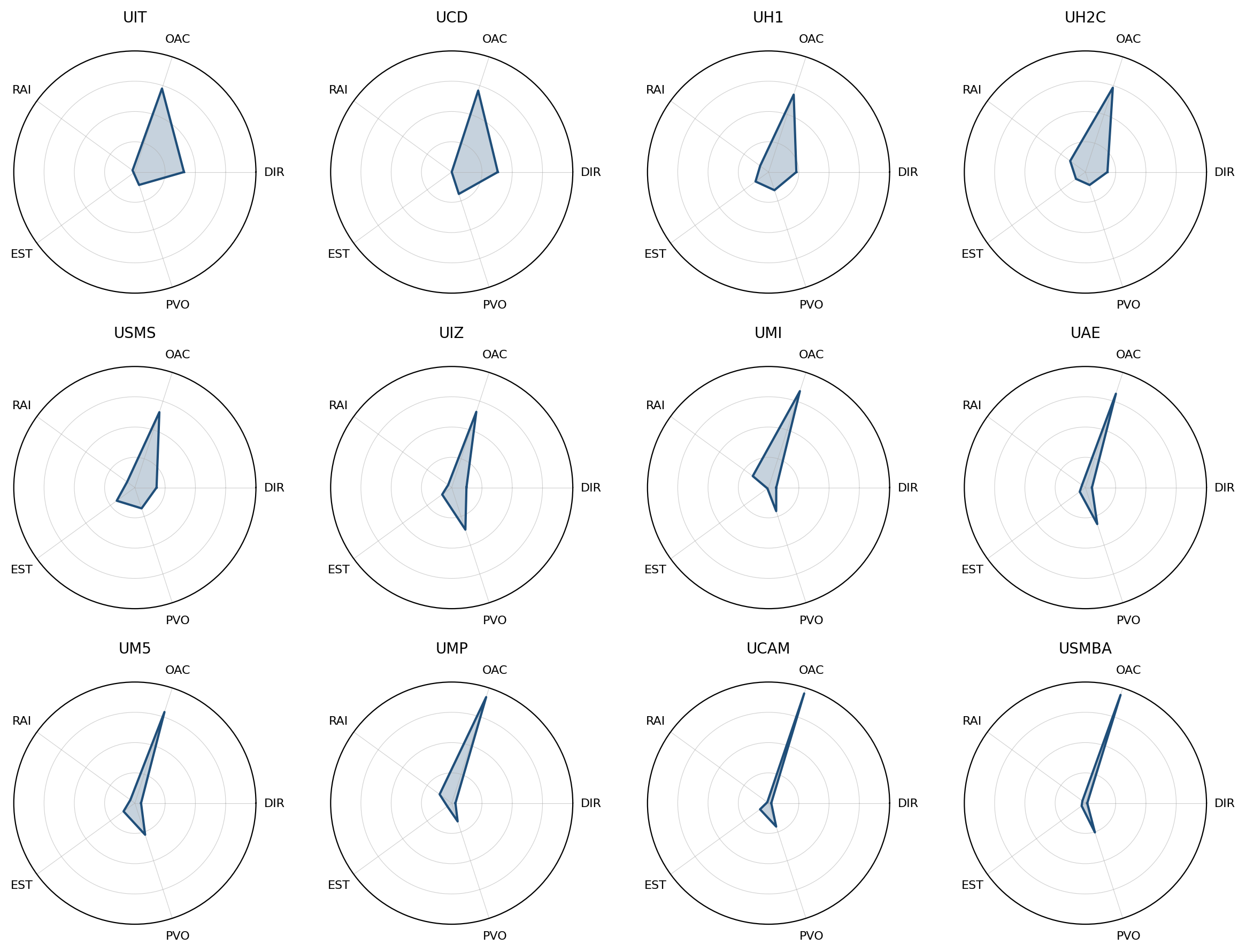
Radar grid — profil discursif par université
1 radar par institution, met en évidence le « shape » discursif distinctif (DIR/OAC/RAI/EST/PVO).
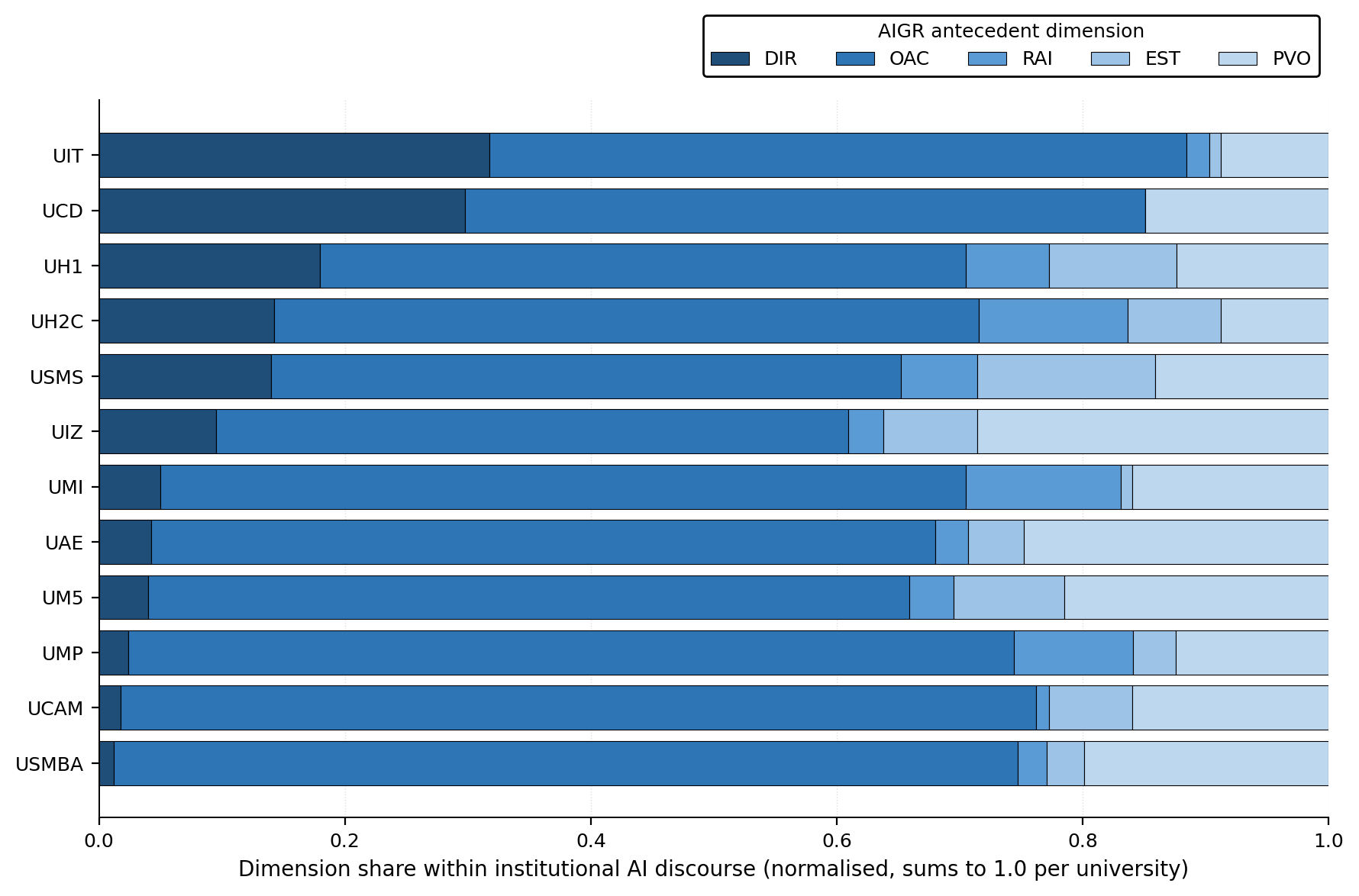
Stacked horizontal bars
Empilement comparatif — utile pour repérer rapidement les institutions à forte/faible diversité discursive.
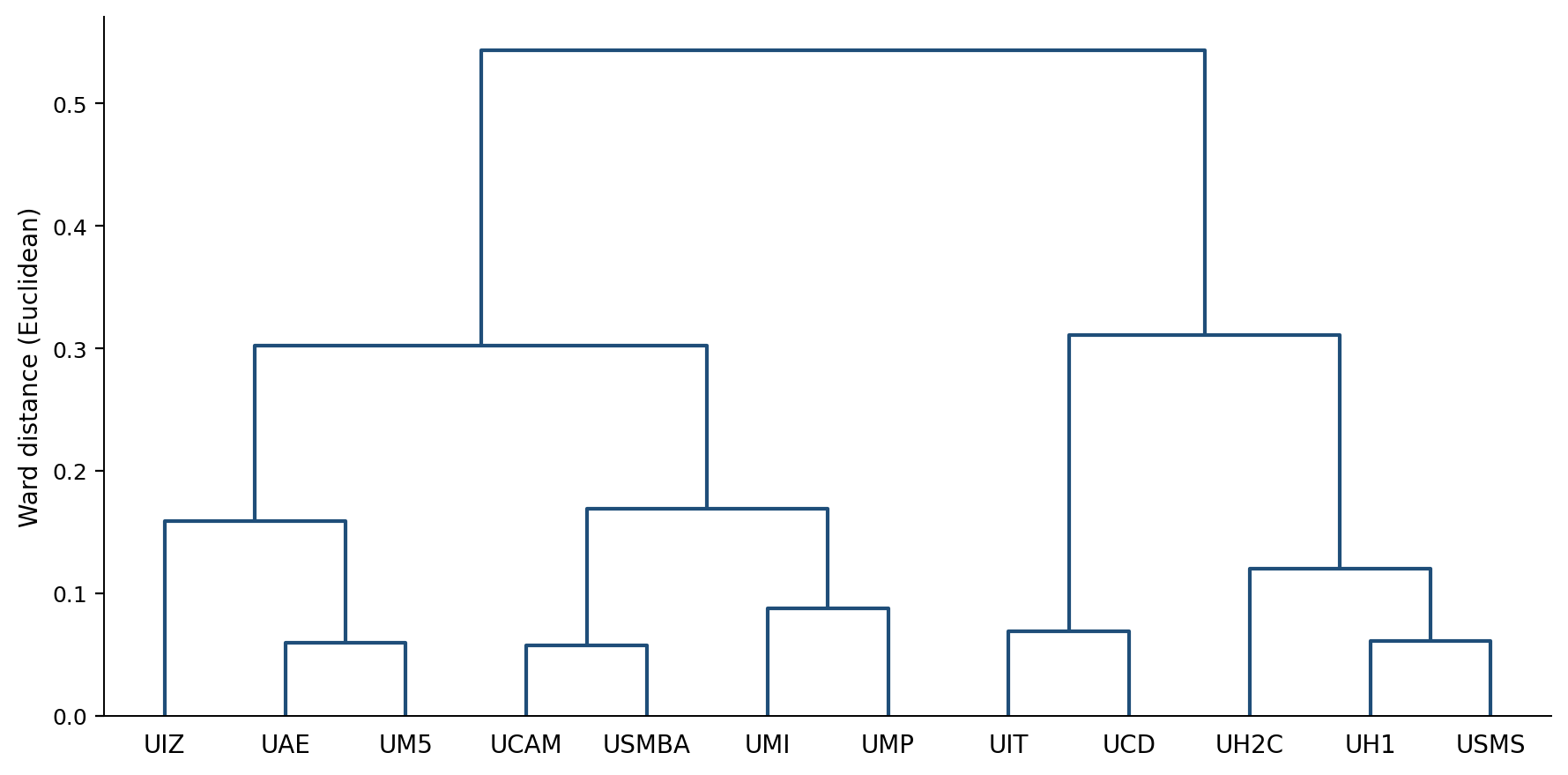
Hierarchical clustering — familles discursives
Dendrogramme : regroupe les universités par similarité de profil discursif (méthode Ward).
Pipeline en 4 stages
- Stage 1 — Scraping respectueux : 50 pages max par université, délai 1.5s, robots.txt honoré, User-Agent identifié comme recherche académique. Profondeur 2 hops depuis pages seed (home + gouvernance + stratégie + actualités + recherche).
- Stage 2 — Préprocessing multilingue : nettoyage HTML, tokenisation par langue (FR/AR/EN), suppression stopwords, normalisation (lowercase + strip diacritiques).
- Stage 3 — Triple analyse :
- TF-IDF → top 30 termes IA discriminants par université
- LDA → 8 topics latents (CountVectorizer + LatentDirichletAllocation, scikit-learn)
- Lexicon mapping → ~200 termes mappés sur DIR/OAC/RAI/EST/PVO, comptage avec word-boundaries (Latin) ou substring (Arabe), normalisation par 1000 mots, puis profil 5D normalisé somme=1.0
- Stage 4 — Visualisations : matplotlib, palette IJIM-friendly (Blues), exports PDF + PNG pour insertion manuscrit.
requirements.txt), data crawl horodatée (manifest CSV + logs). Pipeline complet disponible sur GitHub : ai-governance-readiness-pls-ml.